
There’s a special challenge waiting in drug development’s data ecosystem.
The next time you get dressed in the morning, imagine this: You walk into your closet, look for an outfit, and find nothing but large piles of fiber.
That’s right: this morning, all of your clothes have been transformed into the bundles of individual threads that make them up. Cotton, wool, rayon (go on, admit it), silk, you name it. Your clothes are in there, somewhere. But today, you have to put them all together before you can wear them.
Panicking? I would be!
Have you been transported overnight to your new Kafkaesque reality? Hardly. For someone responsible for CMC workstreams, this experience is an average day with their data resources.
If you’ve been following our series on data governance and integrity, you may know the feeling: you have a regulatory submission coming up, or a report due to leadership, or a risk assessment to handoff to MSAT, and the data you need to create that deliverable is… here, somewhere. In a tangled mass of spreadsheets, PDFs, attachments, and OneDrive folders. And it’s up to you to piece it all together.
Even by drug development’s 3.5-σ standards for data management, CMC data faces particularly acute challenges – ones that continue to delay and degrade many many different critical workflows in the development cycle. But as we’ll see in the third chapter of this series, there’s hope: a new structured approach to managing CMC information that promises to provide a roadmap for modernizing many forms of drug development data.
Let’s take a look!
CMC data is essential to product success. So why isn’t it managed that way?
Despite its vital importance – underpinning every successful regulatory submission, tech transfer, and development pathway – CMC data rarely get the white-glove treatment they deserve. If they’re managed in any purposeful way at all.
Today, far too many drug developers have servers and cabinets full of paper and electronic documents, each one full of countless information “threads” that have to be painstakingly woven into the form of reports, analyses, and submissions. That process can already take weeks or months, and is only growing more burdensome as data volumes exponentially expand every year.
And yet, every day, CMC stakeholders add new “threads” to the mass: more spreadsheets, more paper documents, more PDFs, Word docs, and folders. “Throw it on SharePoint” and “can you email me those results” are as much a part of CMC vocabulary as “have we established temperature parameters for that bioreaction” and “are our CQAs and CPPs fully aligned at this step?”
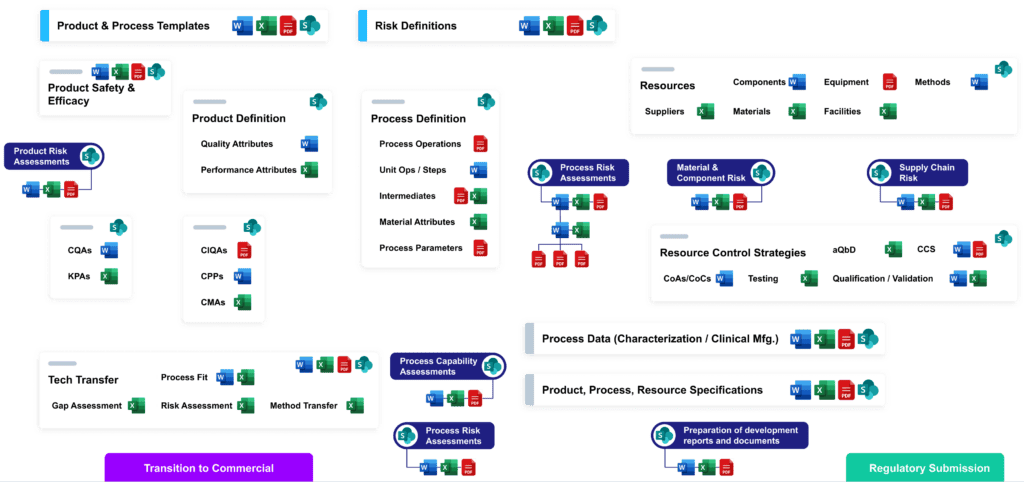
CMC data rarely get the white-glove treatment they deserve. Today, far too many drug developers have closets full of paper and electronic “threads” that have to be painstakingly woven into the cohesive form of each report, analysis, or submission.
For most drug developers, reliance on outdated paper and electronic formats is so ingrained it’s hardly noticed day-to-day. But the cumulative impact on industry performance is becoming inescapable: spiking rates of 483s and other regulatory setbacks, extended time-to-market, and painfully protracted development steps.
As we explored in the second chapter of this series, many drug developers have awakened to the scale of this challenge. At a foundational level, frameworks like FAIR may help the industry bring desperately-needed structure to its data resources. But new paradigms like that take root over time, as organizations rethink their fundamentals of data management and work to build a data culture on principles of modern data governance. What can CMC leaders do now to break today’s vicious cycle of save, upload, forget, redo?
Indeed there is, as a growing number of drug developers are discovering. And it begins with a simple but profound shift of focus: from the documents that continue to slow the industry’s digital development, to the data in those documents.
From collation to structure: How CMC programs need to shift their focus
Today, CMC program’s many paper and electronic documents are a worst-of-both-worlds challenge: each one contains its own isolated bundle of information threads that have to be sorted and untangled, and that then need to be coordinated with numerous other bundles. Is it any wonder that so many regulatory submissions struggle to cross the compliance finish line?
There has to be a better way – and there is.
The premise is simple: instead of creating countless, isolated bundles that need to be meticulously unraveled, focus on the individual threads of information from the start. At QbDVision, we like to refer to those threads as the “atomic data” at the core of every document. And that is where the magic happens.
As a growing number of drug developers are discovering, unlocking digital transformation starts with a simple but profound shift of focus: from the documents that continue to slow the industry’s digital development, to the data in those documents.
Ask yourself what seems like an equally simple question: what is a QTPP? Is it a PDF referenced in countless reports? Is it one of the files you know you need to include in your handoff to MSAT? An attachment you’ve fished out of your inbox a dozen times? Or is it every one of your individual CQAs, CMAs, CPPs, and all the key decisions they anchor – incidentally rolled into a document?
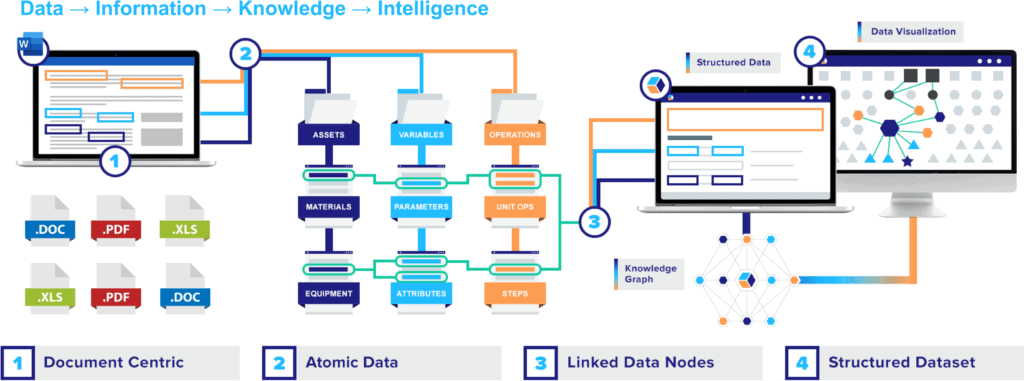
Once you unbundle all those critical data points, every one of them can then be easily linked to upstream, downstream, and lateral steps that each data point influences. And then, all of a sudden, you’ve transformed isolated documents into linked nodes of interconnected data points that can be aggregated into structured datasets – with a host of powerful applications.
Just like that, we’re not talking about threads: we’re talking about a continuous, cohesive digital fabric that can span your entire CMC program, save your workforce countless hours of work, and accelerate critical steps across the development cycle.
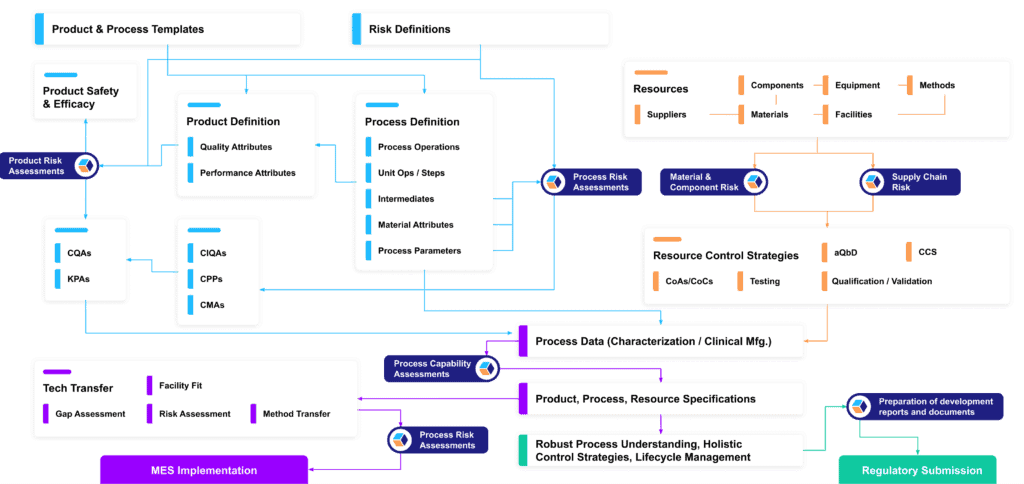
For CMC programs struggling under a growing deluge of data, this can be a transformational approach that unlocks remarkable new levels of robustness, innovation, productivity, and speed. But of course, it’s only feasible if it aligns with regulatory requirements for each stage of the journey to market.
So once we’ve created a digital fabric of CMC data, how can we begin to layer it in ways that support continual compliance?
Aligning CMC data structures with regulatory expectations
At QbDVision, bringing structure to CMC data is what we do best. We’ve had the pleasure of doing so for drug developers of every size, across a wide variety of product types and therapeutic areas.
Here’s a closer look at a typical knowledge framework that we deploy for our customers, and the categories of data that can be tracked and connected:
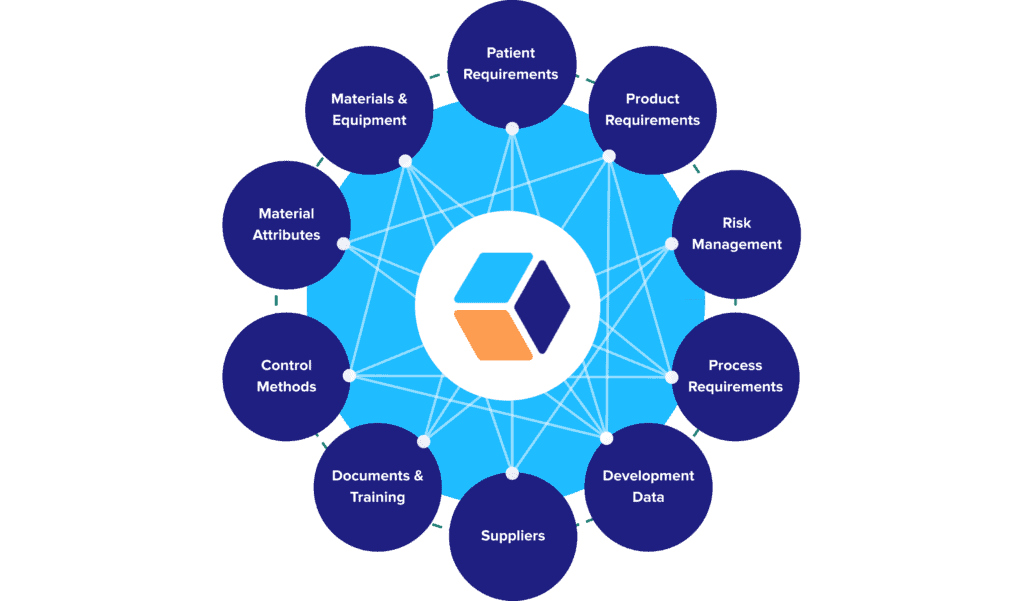
Once in place, though, these connected data sets do more than provide a centralized, integrated data hub for your CMC program. They provide the foundation of a vertically integrated knowledge base rooted in ICH guidelines:
- Fundamental patient, product, and process information naturally make up the base layer of that structure (ICHQ8).
- Our data framework integrates QRM principles by design, making risk assessments and their outputs a fundamental layer of the knowledge base (ICHQ9)
- Data and analytics generated during the development cycle can then be fed directly back into the knowledge base as well, enabling CMC leads to iteratively refine related risk assessments, specifications, and requirements (ICHQ9).
- As general recipes evolve into site-specific recipes, all the tangible assets involved in executing them can be added to the knowledge structure (ICHQ10, ICHQ12).
- And finally, all these layers aggregately support control and lifecycle management strategies that secure and guide the product’s compliance over time (ICHQ8-12).

Structure in one dimension begets structure in all: fully, purposefully integrated project data provide the perfect foundation for integrated layers of knowledge that protect data integrity and compliance over time. That multidimensional framework is an integral feature of QbDVision, and not just essential to our customers’ alignment with ICH guidelines – it also supports multiple applications that further unlock the value of structured CMC data.
…but more on that next time.
Coming up next: Unlocking the power of automated compliance
Like any valuable information resource, structure is just the first step for CMC data. Once it’s in place, you can start to reveal the real value: a host of cost-saving, workflow-accelerating, and insight-generating use cases that can all be built on a foundation of consistently structured data.
In the 4th post in this series, we’ll dive into one of the most powerful applications for CMC programs: automated reporting and compliance. Can you say “weeks of tedious data gathering and collation reduced to a few keystrokes”? Next time, you’ll see how.
Until then, check out some of our team’s other insights on evolving applications, challenges, and best practices for drug development data:
- Data governance & integrity (ch1): The data deluge
- Data governance & integrity (ch2): Structures for maximizing data integrity
- How a FAIR data mindset can accelerate Digital CMC
- Why Knowledge Management and QbD Principles Are Key to Drug Development’s New Supply Chain Era
- With ICH Q13, will continuous manufacturing break through?
GET IN TOUCH
Ready to start structuring your product & process data?
No need to wait for the rest of our series. Reach out to our experts today to learn how we can help.


























































